

Over the weekend, I had a chance to catch up on my favorite AI newsletter from @smol_ai—which updates me daily with highlights and insights. For anyone interested in staying updated with AI, LLMs and agent space, It’s a great resource. Two articles, one from Anthropic and the other from Cognition were discussed and the newsletter challenged us Engineers to reflect on them, so here is my PERSONAL take.
Cognition‘s Walden Yan posted an article with the bold title “Don’t Build Multi-Agents”, while Anthropic shared their perspective on how they’re building a multi-agent research system.
Initially, they seem to contradict each other: one builds a case for multi-agent systems, the other warns against them – a bit of a clickbait (in my opinion), if you ask me. 🙂
But if we dig a little deeper, I think they’re actually addressing the same problem—just from opposite ends of the spectrum. Both articles are well-argued perspectives and I want to strongly advise on reading them well and getting both or their intent clear. Here’s my takeaways:
Article Overview
Anthropic outlines their production-grade multi-agent research system powering Claude. The system is optimized for complex, open-ended research queries where breadth and source diversity are essential. They used a lead-subagent orchestration pattern where each subagent handles part of a research task in parallel. Subagents operate with their own prompts and tools, and results are synthesized by the lead agent. Prompt engineering, memory usage, and outcome evaluations are critical. They also stress that proper task scoping, tool alignment, and subagent role definitions were key to avoiding duplicated work and ineffective searches in early builds. This system includes shared retrieval memory, citation embedding, and even self-ratings from subagents to inform result aggregation.
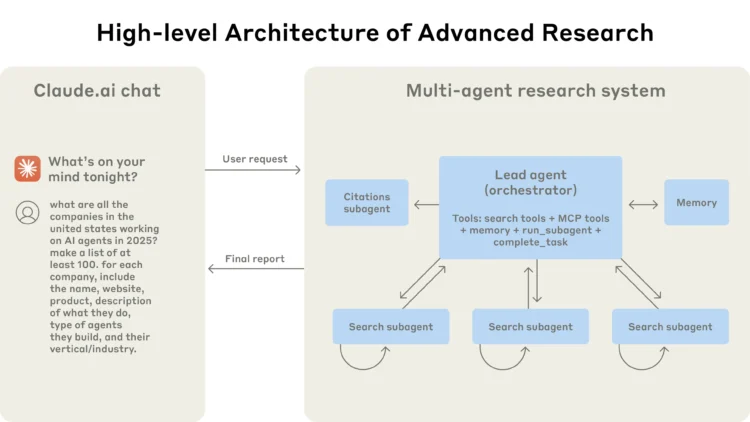
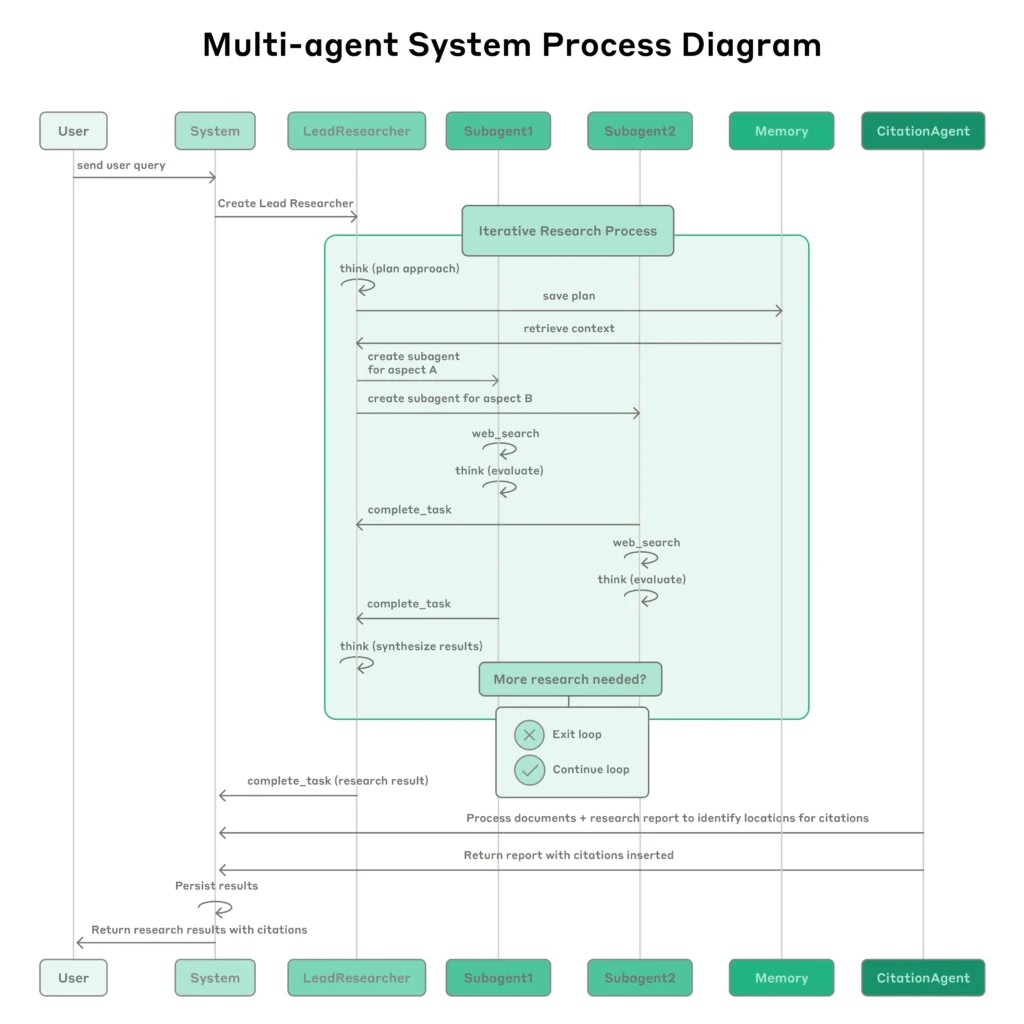
Their internal evaluation showed impressive gains: a 90.2% performance improvement over single-agent baselines. In one benchmark, the system achieved better factual precision and relevance, validated both by human annotators and rubric-based LLM judgment. Importantly, performance gains were found to correlate strongly with token usage—an insight Anthropic highlights with the finding: “token usage alone explains 80% of variance in performance. See Figure below for how this orchestration works in practice.
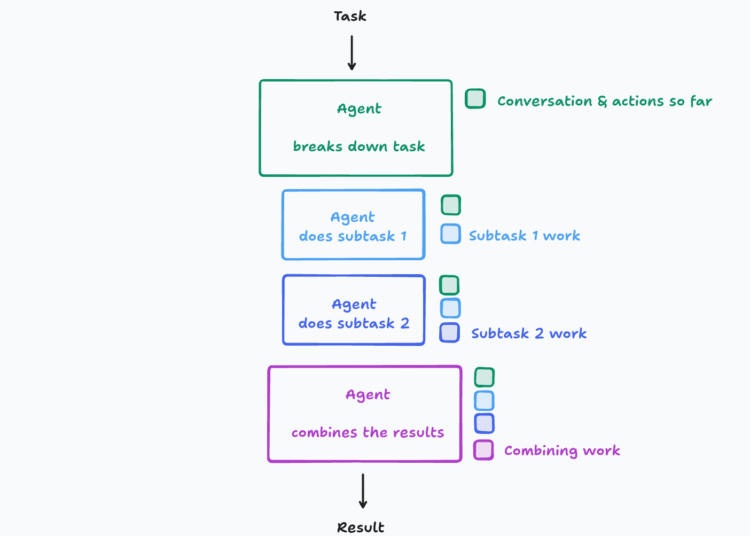
Cognition’s post isn’t anti-multi-agent by principle. It critiques naive implementations of parallel multi-agent architectures that lack memory-sharing and synchronized context. Walden argues that these systems often appear to work because the outputs feel smart, but behind the scenes, subagents are operating in silos—resulting in brittle pipelines that collapse under edge cases or scaling.
Instead, Cognition promotes what they call “context engineering”: the design of agents that accumulate and reason over long-running memory traces. Their approach centers on reliability, decision lineage, and cognitive continuity. They highlight that agents should be engineered like humans reason—step-by-step, in serial, carrying forward every insight, assumption, or ambiguity into the next stage.
Interestingly, they showcase scenarios where even slight misalignments in assumptions across subagents cause logical failures that single-threaded agents would avoid. Their message is clear: if subagents can’t access the full shared state, parallelization becomes counterproductive. As shown below, simple breakdowns can still produce more stable and trustworthy results under this linear model.
I think both articles were highlighting the same sets of problems:
- Context fragmentation
- Token and memory limits
- Orchestration complexity
Anthropic shows how parallelism can lead to scale—but at a high cost in tokens and coordination overhead. Meanwhile, Cognition argues that if agents don’t share context, coherence suffers. They both advocate for a better architecture and a more controlled approach.
From key finding perspective, Anthropic’s main finding is that performance scales with token budget: “Token usage alone explains 80% of system variance.” Their architecture works well when the problem can be split and attacked from many directions, especially when subagents have clearly scoped goals and don’t need to synchronize deeply.
Cognition counters with a reminder: intelligent behavior doesn’t just emerge from scale—it depends on shared understanding. Their solution is to ensure all agent actions carry forward the same assumptions and history. This includes full trace sharing, decision logging, and context summarization between each action. Here is a short comparative analysis:
|
Category |
Anthropic |
Cognition |
|
Objective |
Scalable multi-agent research |
Reliable long-running agent coherence |
|
Architecture |
Lead + Subagents, parallel execution |
Single-threaded agents with shared context |
|
Evaluation Focus |
Outcome-focused, LLM-as-judge, rubric-driven |
Design coherence, reliability, human traceability |
|
Strength |
Breadth and parallelization |
Contextual depth and alignment |
|
Weakness |
High cost, fragility under sync pressure |
Limited scalability for wide search problems |
Reflections
What I love about these two articles is how they both revolve around the same core issue: context. Anthropic scales performance by coordinating many agents with lots of tokens. Cognition aims for resilience and coherence through disciplined, traceable reasoning.
If I have to start building agents, I’d start with Cognition’s approach for most practical applications—especially where reliability and decision integrity matter. But for exploratory tasks or research-heavy use cases, Anthropic’s system is impressive. Cognition’s title might be misleading, but the article itself argues against building undisciplined or disconnected multi-agent systems.
The real takeaway—at least from how I see it—is this: start simple. Design agents with shared context and strong reasoning memory. Avoid parallelism unless the problem truly demands it. And if you do go multi-agent, be intentional and design for inter-agent coherence from the ground up.
But, here are some open question I will leave to the reader or AI enthusiastic to explore:
- Can we combine both philosophies for hybrid systems?
- What tooling makes agent memory and context persistent and portable? I have some emerging frameworks such as Google’s Agent Development Kit with context and session management, but worth the exploration
Shoutout to smol ai for surfacing these reads—perfect Weekend material. If you’re building agents, both posts are worth your time.
Sources
- Anthropic (2025, June 13). How we built our multi-agent research system. Anthropic Blog
- Yan, W. (2025, June 12). Don’t Build Multi-Agents. Cognition Blog